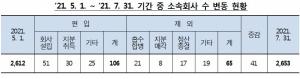
최근 3개월간 대규모기업집단의 소속회사가 4월말 2612개에서 7월말 2653개로 41개사가 증가한 것으로나타났다.또 대규모기업집단 가운데 카카오가 가장 많은 계열사를 늘린 것으로 나타났다.공정거래위원회가 3일 공개한 '2021년 5∼7월 대규모기업집단 소속회사 변동 현황'에 따르면, 71개 대규모 기업집단 소속 회사는 7월 말 현재 2653개로 4월 말 기준치보다 41개가 증가했다.회사설립, 지분취득 등으로 106개 회사가 계열사로 편입된 동시에 흡수합병, 지분매각 등으로 65개 회사가 그룹에서 제외됐다.신규 편입 계열사가 가장
의료 인공지능(AI) 솔루션 개발이 활기를 띠면서 AI 학습을 위한 의료 데이터를 직접 라벨링(labeling·가공)하거나 데이터 라벨링을 반자동화하는 플랫폼을 제공하는 의료 전문 데이터 라벨링 사업이 본격화되고 있다. 데이터 라벨링(일명 전처리 과정)이란 AI 학습데이터를 만들기 위해 원천데이터에 값(라벨)을 붙이는 작업으로, 인공지능 시스템 구축에 없어서는 안 되는 작업이다. 따라서 ‘전문의료진’이 가공한 데이터 라벨링이야 말로 고품질의 의료 소프트웨어를 개발하는 데 필수적인 역할이라고 볼 수 있다. 국내에도 이러한 의료AI 라
한국무역보험공사(K-SURE)는 24일 서울 중구 소재 한국데이터산업진흥원에서 한국데이터산업진흥원(이하 “K-DATA”)과 ‘수출 유망 데이터기업의 해외진출을 위한 업무협약’을 체결했다고 밝혔다.이번 협약은 글로벌 데이터 시장의 성장에 적극적으로 대응하고, 정부가 추진하는 디지털 뉴딜의 주요 기반이 되는 데이터산업의 글로벌화를 지원하기 위해 추진됐다.협약에 따라 K-SURE는 K-DATA와 함께 데이터 관리, 데이터 분석, 머신러닝 등 우수한 데이터 기술을 보유한 중소·중견기업의 수출 경쟁력 제고를 위한 다양한 지원 프로그램을 제공
과학기술정보통신부는 인공지능(AI) 개발에 필수적인 양질의 AI 데이터를 대규모로 구축·개방하는 ‘AI 학습용 데이터 사업’ 공모를 20일부터 시작한다고 밝혔다.동 사업은 3년간 총 65개 기업, 1818명이 참여해, 2017년 4종 750만건, 2018년 7종 1100만건, 2019년 10종 2800만건 등 총 21종 4650만건의 AI 학습 데이터를 구축․개방했다. 이를 통해 4400여명 개발자가 AI 서비스․제품개발에 1만7077회 활용했다.올해는 작년보다 예산과 과제가 2배 늘어난 20개 과제(10개 지정공모, 10개 자유공